

رسم نمودار هیستوگرام یک متغیر کمی بر اساس یک متغیر کیفی
در تعریف منوی توصیفی به آمار تحلیل اشاره شده که این دسته از آمار در حقیقت به توصیف متغیر های نمونه ی تحقیق ما می پردازد و به صورت کاربردی آمار توصیفی در حقیقت خلاصه سازی داده ها در جداول و رسم نمودار های مناسب برای آن به تعریف می شود. اما گاه اتفاق می افتد که محققین عزیز نمودارهای متناسب با هر مقیاس اندازه گیری متغیر ها را برای پژوهش هایشان رسم نمی کنند.
به طور کلی اگر متغیر ها در سطح سنجش اسمی باشند نمودار مناسب برای توصیف ویژگی های نمونه، نمودار دایره ای یا pie chart است. اگر متغیر ها در سطح سنجش ترتیبی باشند نمودار مناسب برای توصیف ویژگی های نمونه، نمودار میله ای یا bar chart است و در نهایت اگر متغیر ها در سطح سنجش فاصله ای یا نسبی باشند نمودار مناسب برای توصیف ویژگی های نمونه، نمودار بافت نگار یا هیستوگرام یا Histogram chart است.
تعریف نمودار هیستوگرام : همانطور که بیان شد این نمودار مناسب داده های با مقیاس فاصله ای یا نسبی(scale) است یا اگر خلاصه تر بخواهیم بیان کنیم برای توصیف ویژگی های متغیر های کمی استفاده می شود. خوب همه عزیزان پیش از این با رسم نمودار بافت نگار برای متغیر های کمی و نحوه رسم آن آشنا شده اند و برای یاد آوری یکی از این نمودار ها در شکل زیر برای متغیر فرسودگی تحصیلی که یک متغیر کمی است آورده شده است.
در نمودار هیستوگرام بالا که برای متغیر کمی burnout یا فرسودگی تحصیلی رسم شده است میبینیم که پراکندگی نمرات این متغیر در بازه ای از صفر تا هفت رسم شده و فراوانی این نمرات بر روی محور عمودی این نمودار را تشکیل داده است. همچنین میانگین نمرات این متغیر ۳٫۷۲ گزارش شده و میزان انحراف معیار آن ۱٫۰۱۷
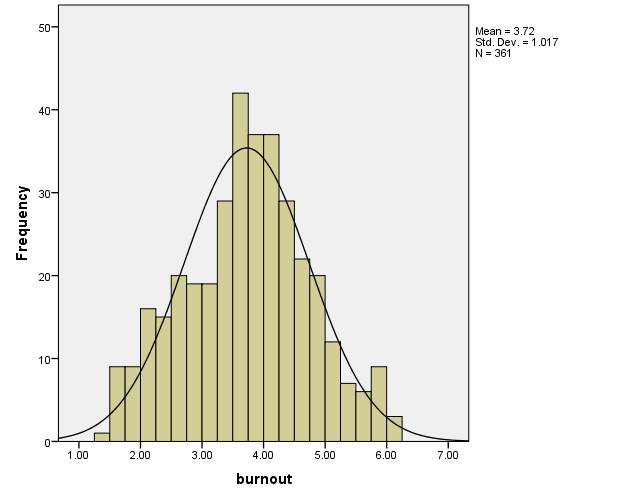 در واقع این نمودار هر سه شاخص گرایش به مرکز، پراکندگی و شکل توزیع را به نمایش گذاشته است. هم مقدار میانگین نمرات به عنوان شاخص اصلی گرایش به مرکز، هم شاخص انحراف معیار به عنوان مهمترین شاخص پراکندگی و در نهایت هم با رسم یک نمودار نرمال مشخص کرده که سهم قابل توجهی از نمرات این متغیر در زیر نمودار نرمال قرار گرفته است. یعنی به نوعی دو شاخص شکل توزیع چولگی و کشیدگی نمرات هم برای آن گزارش شده است. پس این نمودار یک نمودار موفق در خلاصه سازی ویژگی های داده های یک متغیر در قالب یک شکل است. این مهمترین وظیفه آماری توصیفی است.
در واقع این نمودار هر سه شاخص گرایش به مرکز، پراکندگی و شکل توزیع را به نمایش گذاشته است. هم مقدار میانگین نمرات به عنوان شاخص اصلی گرایش به مرکز، هم شاخص انحراف معیار به عنوان مهمترین شاخص پراکندگی و در نهایت هم با رسم یک نمودار نرمال مشخص کرده که سهم قابل توجهی از نمرات این متغیر در زیر نمودار نرمال قرار گرفته است. یعنی به نوعی دو شاخص شکل توزیع چولگی و کشیدگی نمرات هم برای آن گزارش شده است. پس این نمودار یک نمودار موفق در خلاصه سازی ویژگی های داده های یک متغیر در قالب یک شکل است. این مهمترین وظیفه آماری توصیفی است.
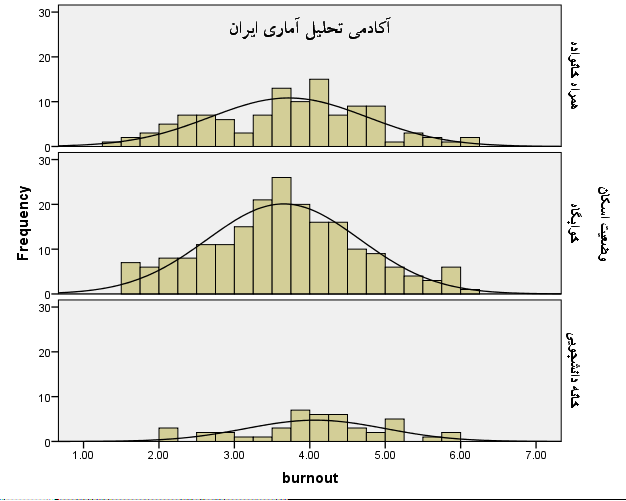
یکی از نمودار های بسیار مفید در راستای توصیف داده های نمونه در بخش آمار توصیفی، رسم نمودار هیستوگرام یک متغیر کمی بر اساس یک متغیر کیفی است. یعنی محققین تلاش کنند که نمودار های متغیر های کمی را در ارتباط کامل با متغیر های کیفی پژوهش(اسمی و رتبه ای) در یک نمودار چند بخشی هیستوگرام مفید بررسی نمایند.
به عنوان مثال فرض نمایید می خواهیم نمودار هیستوگرام همان متغیر کمی فرسودگی تحصیلی را در گروه های مختلف یک متغیر کیفی اسمی مثل نحوه اسکان دانشجویان (همراه خانواده، خوابگاه، خانه دانشجویی) رسم نماییم و ببینیم که شاخص های تمایل به مرکز، پراکندگی و شکل توزیع برای متغیر فرسودگی تحصیلی در این سه بخش متغیر اسکان دانشجویان چگونه است.
چه زمانی نمیتوان از هیستوگرام استفاده کرد؟
هیستوگرامها روشی عالی برای شروع بررسی یک متغیر خاص در هر دسته هستند. با این حال وقتی میخواهیم توزیعهای یک متغیر را در چند دسته از دادهها مقایسه کنیم، هیستوگرامها با مانع خوانایی مواجه میشوند. برای نمونه اگر بخواهیم توزیعهای زمان رسیدن پروازها را بین خطوط هوایی مختلف مقایسه کنیم، میتوانیم از رویکردهای مختلفی استفاده کنیم. یکی از رویکردهای ممکن که البته چندان بهینه نیست، تجمیع هیستوگرام همه ایرلاینها روی یک نمودار واحد است.
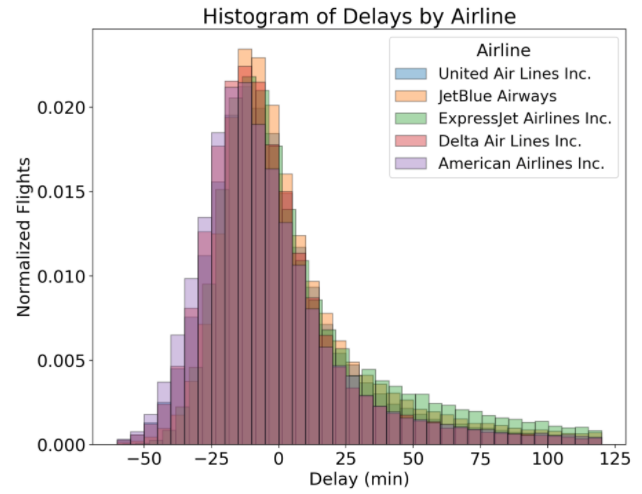 توجه داشته باشید که محور y برای نشان دادن تعداد متفاوت پروازها بین خطوط هوایی مختلف نرمالسازی شده است. برای این کار آرگومان norm_hist = True به تابع sns.distplot ارسال میشود.
توجه داشته باشید که محور y برای نشان دادن تعداد متفاوت پروازها بین خطوط هوایی مختلف نرمالسازی شده است. برای این کار آرگومان norm_hist = True به تابع sns.distplot ارسال میشود.
این نمودار چندان مفید نیست! همه ستونهایی که روی هم افتادهاند در مجموع باعث شدهاند که امکان خواندن مقادیر و مقایسه بین خطوط هوایی وجود نداشته باشد. در ادامه برخی راهحلهای رایج برای این مشکل را بررسی کردهایم.
09357258425
www.pajuha.ir
info@pajuha.ir
سفارش ترجمه تخصصي
جهت متغیرهای کمی شاخصهای پراکندگی به صورت زیر میباشد:
میانگین مربع پر کاربردترین شاخص پراکندگی است. به عبارت دیگر، واریانس به معنی میانگین مربع فاصلهی مقادیر یک متغیر از میانگین آن متغیر است که فرمول محاسبهی آن به بصورت :
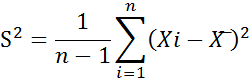
ضریب تغییرات به واحدی که متغیر مربوط به آن اندازهگیری شده است، بستگی ندارد و میتوان پراکندگی دو متغیر متفاوت را با هم مقایسه نمود.
![]()
جهت مشخص کردن موقعیت نمره یک فرد نسبت به نمرات دیگر افراد نمونه نمرات را استاندارد میکنیم. ابتدا نمره مشاهده شده را از میانگین کسر و سپس بر انحراف معیار تقسیم میکنیم.
Skewness یا چولگی:
میزان عدم تقارن توزیع را اندازهگیری و بیان میکند، این میزان برای توزیع نرمال صفر است.
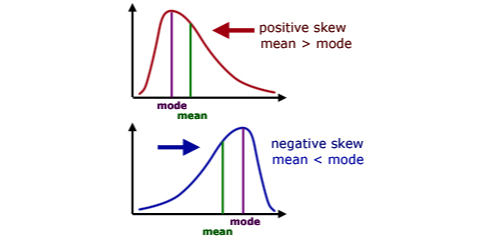
نشان دهنده قلهمندی و درجه اوج یک توزیع احتمالی است که برای توزیع نرمال عدد 3 است.
اگر بیشتر از 3 شود توزیع تیزتر از نرمال است.
اگر کمتر از 3 شود توزیع پهن تر از نرمال است.
از این منو جهت محاسبه آمارههای توصیفی، تشکیل جداول فراوانی و جداول توافقی استفاده میشود. فرمانهای این منو به شرح زیر میباشد:
1- فرمان Frequencies فراوانی

2- فرمان Descriptive توصیفی
3- فرمان… Explore
4- جدول توافقی Crosstabs
از این فرمان جهت تشکیل جداول فراوانی متغیرهای اسمی و رتبه ای استفاده میشود. همچنین از این جدول، جهت متغیر کمی نیز استفاده می شود ولی لازم است آن متغیر را مجدد کدگذاری کنیم.
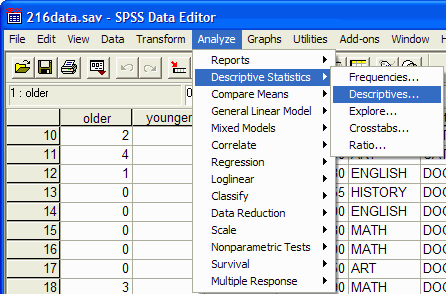
برای اجرای این فرمان، از منوی Analyze به ترتیب زیر منوهای Descriptive Statistics و Frequencies را انتخاب نمایید تا کادر زیر نمایان شود:
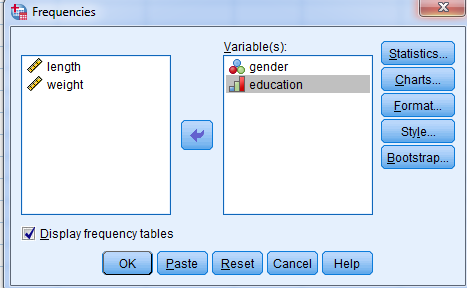
اسامی متغیرها در سمت چپ، فهرست شدهاند یک یا چند متغیر را به سمت راست منتقل کنید.
با کلیک روی دکمهی Statistics… کادر زیر نمایان میشود.
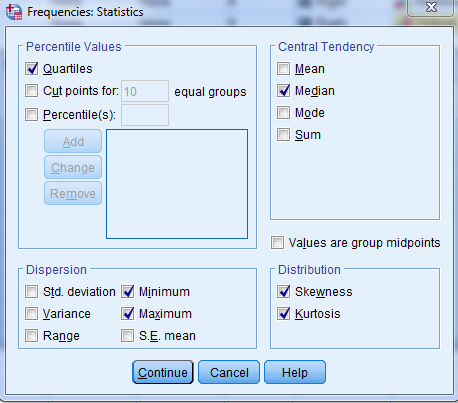
که دارای 4 قسمت میباشد.
در قسمت percentile values میتوانید( چارکها، صدکها و نقاط برش) را انتخاب نمایید.
در قسمت Central Tendency میتوانید شاخصهای( مرکزی میانگین، میانه، مد، مجموع )را انتخاب کنید. در قسمت Dispersion میتوانید شاخصهای پراکندگی ( مینیمم، ماکزیمم، واریانس، انحراف معیار، دامنه و خطای استاندارد)را بسته به نیاز انتخاب کرد.
در قسمت آخر Distribution میتوان مقادیر(چولگی و کشیدگی)را انتخاب کرد. روی دکمهی Continue کلیک کنید تا به کادر قبل بازگردید. روی دکمهی …Charts کلیک کنید تا کادر زیر نمایان شود:
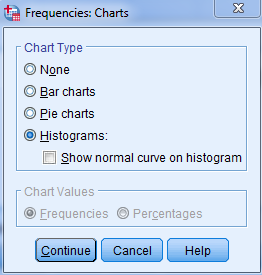
شامل دو قسمت است که به شرح آن میپردازیم:
قسمت اول Chart Type شامل چهار گزینه با انتخاب گزینهی None هیچ نموداری رسم نمیشود، با انتخاب گزینهی Bar charts نمودار میله ای، Pie charts نمودار دایرهای و Histograms نمودار هیستوگرام(مستطیلی) رسم میشود.
بعد از انتخاب گزینهی هیستوگرام، گزینهی With normal curve فعال میشود که با تیک زدن آن یک منحنی نرمال روی نمودار هیستوگرام نمایش مییابد.
در قسمت دوم، یعنیChart Values میتوان نوع نمایش مقادیر نمودار را تعیین کرد.
با انتخاب گزینهی Frequencies نمودار بر حسب مقادیر فراوانی و با انتخاب گزینهی Percentages نمودار بر حسب درصد فراوانی رسم میشود. این قسمت تنها زمانی فعال میشود که یکی از گزینههای Bar charts و Pie charts را انتخاب کرده باشید. اکنون روی دکمه Continue کلیک کنید تا به کادر قبل بازگردید.
توجه کنید که اگر تیک مقابل گزینه Display Frequency tables را در کادر Frequencies بردارید، جدول فراوانی تشکیل نمیشود. پس از انتخاب گزینههای مورد نظر روی دکمه ok کلیک کنید تا خروجی نمایش یابد.
09357258425
www.pajuha.ir
info@pajuha.ir
سفارش ترجمه تخصصی
آموزش کامل و تصویری آمار توصیفی در نرم افزار Spss
این آموزش به شما نحوه استفاده از SPSS نسخه ۲۰۱۷ را برای تجزیه و تحلیل داده های اکتشافی و آمار توصیفی نشان می دهد. شما برای ایجاد نمودار ستونی ،توزیع فراوانی ، کشیدن ساقه و برگ ، رسم کردن نمودارجعبه ای ، محاسبه استاندارد معیارهای گرایش مرکزی( میانگین، میانه و مد )، محاسبه استاندارد معیارهای پراکندگی(دامنه، فاصله بین چارک اول و سوم، انحراف معیار، واریانس) و محاسبه معیارهای منحنی توزیع و ناهموار از SPSS استفاده خواهید کرد.
این ویدیو توضیحی کلی در ارتباط با آمار توصیفی spss ارائه می کند که بهتر است قبل از مطالعه بقیه پست، آن را تماشا کنید:
ویدیو توسط همکار عزیزم جناب موذن تهیه شده است.
دستور بسامد ها (تناوبها)می تواند برای تعیین چارک ها ،درصدها،شاخصهای مرکزی( میانگین، میانه و مد )،اندازه گیری پراکندگی(دامنه ،انحراف معیار، واریانس، حداقل و حداکثر( معیارهای منحنی توزیع و ناهمواریها ، و ایجاد نمودار ستونی ها مورد استفاده قرار گیرد. این فرمان در Analyze یافت می شود| آمار توصیفی| تناوب ها (این مختصرنویسی برای کلیک کردن بر روی آیتم های منو تجزیه و تحلیل در بالای پنجره است و سپس کلیک بر روی آمار توصیفی از منوی کشویی و فرکانس (تناوب)ها از منوی pop up)
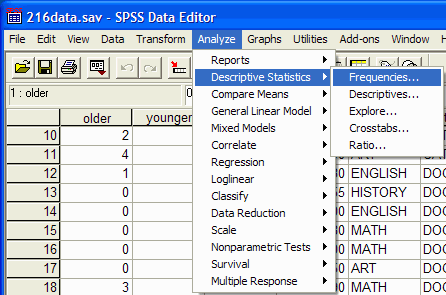
کادر محاوره ای فرکانس ها ظاهر خواهد شد:
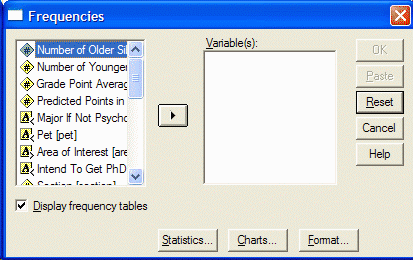
متغیرهایی را که میخواهید تجزیه و تحلیل کنید با کلیک بر روی آن در کادر چپ از کادر محاوره فرکانسها انتخاب کنید. سپس بر روی دکمه فلش کلیک کنید تا متغیر را به قسمت متغیرها منتقل کنید:
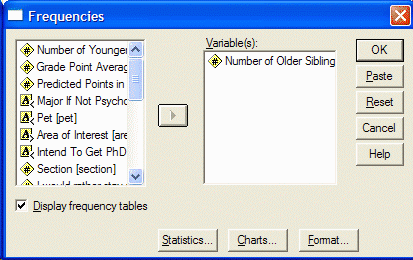
اگر می خواهید یک توزیع تناوبی داشته باشید اطمینان حاصل کنید که نمایش جداول تناوبی نمایش داده شود با کلیک روی دکمه آمار،مشخص کنید که کدام آمار را می خواهید انجام دهید. کادر محاوره ای(= آمار) Statistics ظاهر خواهد شد:
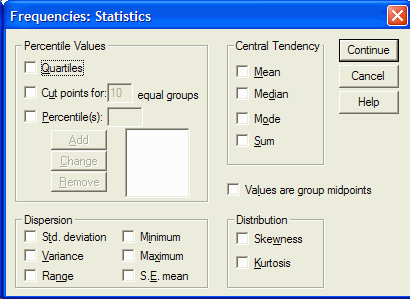
از کادر محاوره ای Statistics ، روی آمار مورد نظر که می خواهید انجام دهید کلیک کنید. برای محاسبه یک درصد داده شده، در مربع سمت چپ درصد (ها) کلیک کنید. درصد مورد نظر را تایپ کنید و روی دکمه افزودن(add) کلیک کنید. هنگامی که شما تمام آمار مورد نظر را انتخاب کردید ( به عنوان مثال میانگین، میانه، مد، انحراف معیار، واریانس، دامنه ، و غیره ) روی دکمه Continue کلیک کنید. با کلیک کردن بر روی دکمه Chart مشخص کنید که می خواهید کدام نمودار نمایش داده شود. کادر محاوره ای نمودار ظاهر خواهد شد
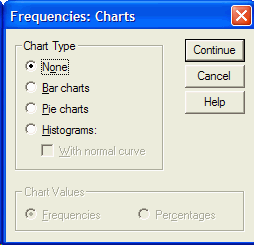
روی نمودار دلخواه (معمولا نمودار ستونی) کلیک کنید و روی دکمه Continue کلیک کنید. در کادر محاوره ای فرکانس (تناوب )ها روی OK کلیک کنید. نمایشگر خروجی SPSS ظاهر خواهد شد. در نمایشگر خروجی SPSS، شما آمار و جدول مورد نظر را مشاهده خواهید کرد. این همان چیزی است که خروجی آمار به نظر می رسد. در این فهرست ضوابط مورد نیاز از گرایش به مرکزی، اندازه گیری های پراکندگی، اندازه گیری های ناهموار و منحنی توزیع ، و چارک ها و درصد موارد فهرست شده است.
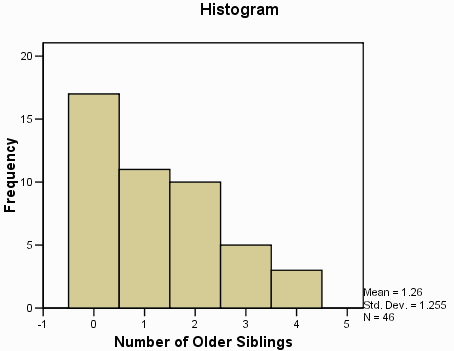
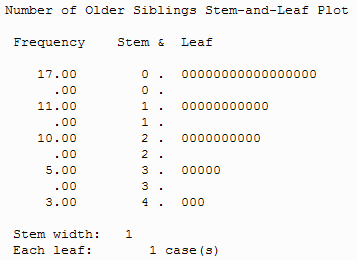
آمار تعداد خواهرهای بزرگتر
| ۴۶۰
۱٫۲۶ ۱٫۰۰ ۰ ۱٫۲۵۵ ۱٫۵۷۵ .۶۷۸ .۳۵۰ -.۵۴۳ .۶۸۸ ۴ .۰۰ ۱٫۰۰ ۲٫۰۰ | valid missing(غیر قانونی)
میانگین میانه مد انحراف معیار واریانس ناهموار(مورب بودن) استاندارد خطای مورب بودن منحنی توزیع استاندارد خطای منحنی توزیع دامنه درصد موارد ۲۵ ۵۰ ۷۵ |
خروجی دارای دو ستون است. ستون سمت چپ آمار نامیده می شود و ستون سمت راست مقدار آماری را می دهد. به عنوان مثال، میانگین این داده ها ۱٫۲۶ است(از آنجا که مجموعه داده های شما ممکن است متفاوت باشد، ممکن است یک مقدار متفاوت دریافت کنید. هنگامی که توزیع درهم شکسته می شود درجه کشیدگی بیشتر از ۰ است . منحنی توزیع برای یک توزیع نرمال ۰ است.
نکته مهم! آموزش توابع آماری اصلی در نرم افزار Spss (یا Statistic functions)
چنانچه به پایین اسکرول کنید، توزیع فراوانی را مشاهده خواهید کرد.
| درصد تجمعی | درصد صحیح | درصد | فراوانی | |
| ۳۷۶۰٫۹
۸۲٫۶ ۹۳٫۵ ۱۰۰ | ۳۷۲۳٫۹
۲۱٫۷ ۱۰٫۹ ۶٫۵ ۱۰۰ | ۳۷۲۳٫۹
۲۱٫۷ ۱۰٫۹ ۶٫۵ ۱۰۰ | ۱۷۱۱
۱۰ ۵ ۳ ۴۶ |
۱ ۲ ۳ ۴ جمع کل |
نمودار ستونی
دستورالعمل توصیفی می تواند برای تعیین اندازه گیری گرایش مرکزی (میانگین) ، اندازه گیری پراکندگی (دامنه، انحراف معیار، واریانس، کمینه و بیشینه( ، و معیارهای منحنی توزیع وکشیدگی استفاده شود.این فرمان در تجزیه و تحلیل کردن/ آمار توصیفی/ توصیفات یافت می شود . (این مختصر نویسی برای کلیک کردن بر روی آیتم منو Analyze ( تجزیه و تحلیل( در بالای پنجره، و سپس کلیک بر روی آمار توصیفی از منوی کشویی و Descriptives (توصیفات ) از منوی pop up است) :
کادر نمایش توصیفی ظاهر خواهد شد:
متغیرهایی را که میخواهید تجزیه و تحلیل کنید، با کلیک کردن روی آن در قسمت سمت چپ پنجره جعبه توصیفی، انتخاب کنید. سپس بر روی دکمه فلش کلیک کنید تا متغیر را به قسمت متغیرها منتقل کنید
با کلیک روی دکمه گزینه ها مشخص کنید کدام آمار را می خواهید انجام دهید. کادر انتخاب گزینه ظاهر خواهد شد:
آماری را که شما نیازدارید با کلیک کردن بر روی آنها (مانند میانگین، انحراف معیار، واریانس، دامنه، حداقل، و غیره) انتخاب کنید. سپس بر روی دکمه Continue کلیک کنید. روی دکمه OK در کادر محاوره Descriptives (توصیفات) کلیک کنید. نمایشگر خروجی SPSS، با نتایج شما در آن ظاهر می شود. شرح ذیل نمونه ای از خروجی است:
| منحنی توزیع | کشیدگی | واریانس | ضریب | میانگین | بیشینه | کمینه | دامنه | نام | ||
| ضریب خطا | آمار(رقم) | ضریب خطا | آمار(رقم) | آمار(رقم) | آمار(رقم) | آمار(رقم) | آمار(رقم) | آمار(رقم) | آمار(رقم) | |
| ۶۸۸٫ | ۵۴۳٫- | ۳۵۰٫ | ۶۷۸ . | ۱٫۵۷۵ | ۱٫۲۵۵ | ۱٫۲۶ | ۴ | ۰ | ۴ | ۴۶ تعداد خواهر بزرگتر۴۶ درست (listwise) |
خروجی ارزش های آمار درخواست شده را می دهد.
فرمان اکتشاف می تواند برای تعیین اندازه گیری گرایش مرکزی استفاده شود(میانگین و میانه) اندازه گیری پراکندگی (دامنه،فاصله بین چارک اول و سوم،انحراف معیار، واریانس، حداقل و حداکثر ) ،میزان منحنی توزیع و کشیدگی،و آماده سازی نمودارهای ستونی ،کشیدن ساقه و برگ،و کشیدن نمودارجعبه توکی(Tukey) ،این فرمان در (Analyze| Descriptive Statistics | Explore ) یافت می شود:
جعبه محاوره ای ظاهر خواهد شد:
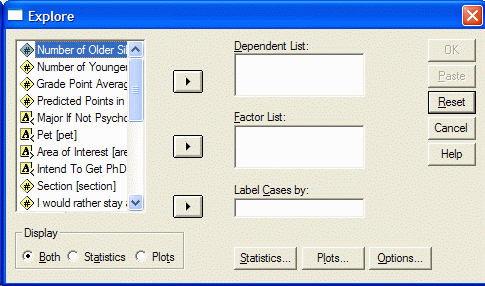
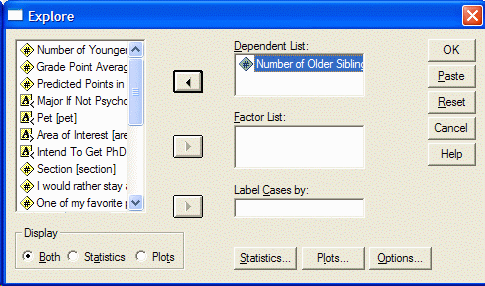
متغیر (ها) را که می خواهید تجزیه و تحلیل کنیدبا کلیک کردن بر روی آن در قسمت سمت چپ جعبه محاوره ای انتخاب کنید. سپس بر روی دکمه فلش بالایی کلیک کنید تا متغیر را به لیست وابسته منتقل کنید:
با کلیک کردن بر روی دکمه Plots ،مشخص کنید کدام موضوع(طرح)را می خواهید تهیه کنید. کادر محاوره ای Plots ظاهر خواهد شد:
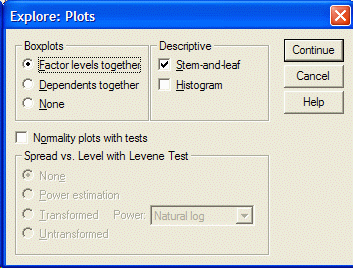
توزیع هایی را که میخواهید با کلیک کردن روی آنها انتخاب کنید (به عنوان مثال میانگین ،ساقه و برگ و نمودار ستونی). سپس بر روی دکمه Continue کلیک کنید. بر روی دکمه OK در کادر محاوره جستجوگر کلیک کنید. نتایج شما در نمایشگر خروجی SPSS ظاهر می شود.
| ۱۸۵٫۳۵۰٫
۶۸۸٫ | ۱٫۲۶۸۹٫
۱٫۶۳ ۱٫۱۸ ۱٫۰۰ ۱٫۵۷۵ ۱٫۲۵۵ ۰ ۴ ۴ ۲ ۶۷۸٫ ۵۴۳٫- | میانه تعداد خواهر بزرگترکران پایین اعتماد به نفس ۹۵ ٪
کران بالا فاصله برای میانگین ۵٪ کاهش یافته است میانه واریانس انحراف معیار کمینه بیشینه دامنه دامنه میان چارکی کشیدگی منحنی توزیع |
خروجی مقادیر آمار درخواست شده را می دهد
اگر شما پایین بروید، طرح درخواست شده را مشاهده خواهید کرد.
نکته مهم! آموزش اصولی تحلیل رگرسیون خطی در نرم افزار SPSS (با مثال ملموس)
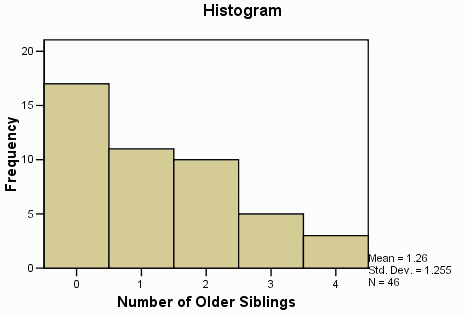
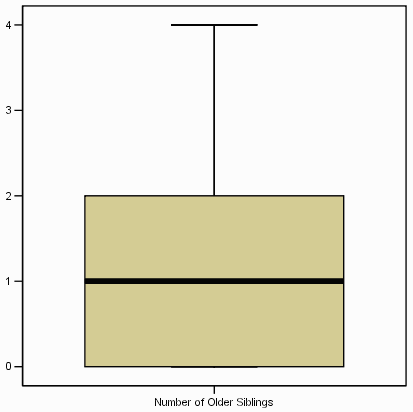
نمودار جعبه ای توکی اول نشان داده شده (پایین جعبه) و سوم(بالای جعبه) چارک ها ( معادل ۲۵ و ۷۵ درصد ) میانه (خط افقی در جعبه) دامنه( به استثنای ناپایدار و نمرات افراطی)(الیاف ریز یا خطوطی که از جعبه گسترش می یابند) غلظت (یک دایره نشان دهنده هر خروجی است – عدد کنار خروجی تعداد مشاهدات است ) خروجی به عنوان نمره ای بین ۱٫۵ تا ۳ طول جعبه بطوز پیوسته از لبه بالایی یا پایینی جعبه تعریف می شود (به یاد داشته باشید که جعبه ۵۰ درصد میانه امتیاز را نشان می دهد). حداکثر نمره به عنوان نمره ای است که بیشتر از ۳ طول جعبه از لبه بالایی یا پایین تر جعبه تعریف شده است.
09357258425
www.pajuha.ir
info@pajuha.ir
سفارش ترجمه تخصصی
خروجی Frequencies
جدول فراوانی چهار نوع کاربرد در spss دارد به شرح ذیل توضیح داده می شود.
توصیف خروجی spss اجراء دستور Statistics
Analysis⇒ Descriptive Statistics⇒ Frequencies ⇒ Statistics
۱- samplings: این آماره نشان می دهد از مجموع پاسخ گویان ۷۴۹ نفر، ۹ نفر سن خود را به هر دلیلی بیان نکرده اند.
۲- Central tendency: حاصل اجراء این گزینه انجام سه آماره گرایش مرکزی است. میانگین سنی نشان می دهد، پاسخ گویان ۳۴ سال و شش ماه (۵۱ درصد یک سال) سن دارد. میانه سنی نشان می دهد ۵۰ درصد جمعیت نمونه ۳۰ سال و هشت ماه دارند. همچنین بر اساس نما، اکثر پاسخ گویان ۲۲ ساله بوده اند. با توجه به تعریف جوانی جمعیت، شاخص های گرایش مرکزی نشان می دهد جمعیت مورد بررسی جوان هستند.
۳- dispersion: این آماره ها (انحراف استاندارد،واریانس، دامنه تغییرات، منیمم، ماکسیمم و انحراف متوسط میانگین) نشان می دهد توزیع نمونه یکنواخت نبوده و خیلی پراکنده هستند.
۴- distribution:مقدار آماره های کشیدگی و چولگی کمتر از قدر مطلق عدد ۲ می باشند. این مقدار نشان می دهد داده ها از توزیع تقریباً نرمال برخوردار هستند.




 سن: (توصیف سن پاسخ گویان بر اساس جدول)
سن: (توصیف سن پاسخ گویان بر اساس جدول)
در مجموع سن ۵/۱۱ درصد پاسخ گویان کمتر از ۲۰ سال، ۵/۱۳ درصد ۲۰ تا ۲۴ سال، ۱/۲۰ درصد ۲۵ تا ۲۹ سال، ۳/۲۰ درصد ۳۰ تا ۳۹ سال، ۱/۱۸ درصد ۴۰ تا ۴۹ سال و ۴/۱۵ درصد بیشتر از ۵۰ سال بوده است. ضمن این که ۱/۱ درصد پاسخ گویان (۹ نفر) سن خود را اظهار نکرده اند. میانگین سنی پاسخ گویان ۵۱/۳۴ بوده است. همچنین کمترین سن ثبت شده پاسخ گویان ۱۵ سال و بیشترین آن ۷۴ سال بوده است (جدول ۲).
 توصیف خروجی SPSS اجرای دستور chart
توصیف خروجی SPSS اجرای دستور chart
Analysis ⟹ Descriptive Statistics ⟹ Frequencies ⟹ chart
سن: (توصیف سن پاسخ گویان بر اساس نمودار)
در مجموع سن ۶/۱۱ درصد پاسخ گویان کمتر از ۲۰ سال، ۶/۱۳ درصد ۲۰ تا ۲۴ سال، ۳/۲۰ درصد ۲۵ تا ۲۹ سال، ۷/۲۰ درصد ۳۰ تا ۳۹ سال، ۳/۱۸ درصد ۴۰ تا ۴۹ سال و ۶/۱۵ درصد بیشتر از ۵۰ سال بوده است. ضمن اینکه ۱/۱ درصد پاسخ گویان (۹ نفر) سن خود را اظهار نکرده اند. میانگین سنی پاسخ گویان ۵۱/۳۴ بوده است. همچنین کمترین سن ثبت شده پاسخ گویان ۱۵ سال و بیشترین آن ۷۴ سال بوده است (نمودار).
 توصیف خروجی ارجای Format
توصیف خروجی ارجای Format
Analysis ⟹ Descriptive Statistics ⟹ Frequencies ⟹ format
در جدول زیر چهار نوع مرتب شدن جدول فراوانی داده های متغیر نشان داده شده است.
۱- این جدول بر اساس ارزش های متغیر به صورت صعودی مرتب شده است
۲- این جدول بر اساس ارزش های متغیر به صورت نزولی مرتب شده است
۳- این جدول بر اساس فراوانی داده ها به صورت صعودی مرتب شده است
۴- این جدول بر اساس فراوانی داده ها به صورت صعودی مرتب شده است

 خروجی Style و bootstrap
خروجی Style و bootstrap
این دو خروجی برای یادگیری ضرورت ندارند.
09357258425
info@pajuha.ir
سفارش ترجمه تخصصي
تعریف خواص متغیرها در spss
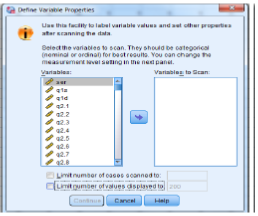
برای انجام یک پروژه آماری به کمک نرم افزار spss ابتدا باید متغیرها در صفحه variable view تعریف و سپس داده ها را وارد کرد. گاهی برخی محققین داده ها را در نرم افزارهای دیگر مانند DE و Exel و … وارد می کنند و سپس از طریق spss فراخوان می شود. در این صورت بهتر است مشخصات متغیرها داده ها در spss برای تجزیه و تحلیل آماری تعریف شود، هدف از نگارش این متن کمک به پژوهشگران آمار برای تجزیه و تحلیل آماری مناسبی توسط نرم افزار spss می باشد. ورود داده ها در spss به دو صورت امکان پذیر است یا مستقیماً در نرم افزار spss وارد می شود یا این که ابتدا در یک صفحه گسترده مثل DE و exel وارد می گردد سپس داده ها در نرم افزار spss فراخوان می شود، بعد ار وارد کردن داده ها می توان از منوی Data، گزینه ی Properties Define Variable
… (تعریف ویژگی های متغیر) مشخصات مربوط به متغیرها رو مشاهده یا آن ها را تغییر داد.
از مستطیل سمت چپ متغیرهای مورد نظر رو انتخاب کرده با کلیک بر روی ► آن ها رو به کادر to Scan Variables
منتقل کرد.
گاهی در یک پروژه آماری برخی متغیرهای محدودی برای تجزیه و تحلیل در نرم افزار spss لازم است. برای مشاهده مشخصات محدوده ای از متغیرها می توان از دو کادر انتهایی استفاده کرد. کار اسکن از ابتدای داده ها تا شماره سطری که در کادر اول (Limit number of cases scanned to) وارد می شود انجام می گیرد. در کادر دوم (Limit number of values displayed to) عدد مربوط به تعداد داده هایی که قرار است مشخصاتش مشاهده گردد وارد می شود. بعد از انتخاب متغیرها با کلیک بر روی Continue در پنجره ی Define Variable Properties می توان مشخصات متغیرها را مشاهد کرد.
می توان در پایین کادر Scanned Variable List لیست باکس Define Variable Properties، متغیرهای انتخاب شده را مشاهده کرد علاوه بر آن با کلیک بر روی هر یک از متغیرها می توان مشخصات مربوط به آن متغیر انتخاب شده را مشاهده کرد علاوه بر آن با کلیک بر روی هر یک از متغیرها می توان مشخصات مربوط به آن متغیر در کادر Value Label grid مشاهده کرد.
در یک پروژه آماری که توسط نرم افزار spss انجام می گیرد بهتر است که بر چسب متغیر و مقیاس آن تعیین شود. بر تعریف چسب متغیر را می توان از قسمت Label و مقیاس آن از قسمت Measurement Level استفاده کرد. با انتخاب گزینه Suggest، نرم افزار spss مقیاسی پیشنهاد می کند – دقت شود. برای تعیین و تغییر نوع متغیر، پهنای متغیر و تعداد ارقام اعشار متغیر از قسمت type اقدام می شود. داده هایی که دارای بر چسب نیستند در قسمت Unlabeled values نمایش داده می شوند. برای ایجاد بر چسب جدید برای داده ی مورد نظر یا ویرایش بر چسب های قبلی از ستون در قسمت Value Label grid اقدام می گردد. برای تعریف بر چسب مقادیر (Value Labels) جدید برای متغیر از دکمه Attributes استفاده می شود. در این قسمت برای هر نام متغیر یک بر چسب دلخواه مشخص می شود. گاهی در جمع آوری داده ها به هر علتی بی پاسخی به وجود می آید. در اصطلاح آماری به آن ها داده ها گم شده گفته می شود، این مقادیر گم شده و بی معنا را می توان spss با کدهای مشخص کرد، حداکثر سه مقدار گم شده را می توان در ستون missing تعریف کرد، spss برای تجزیه و تحلیل داده ها مقادیر missing را در نظر نمی گیرد.
برای سهولت و سرعت کار در spss در صورت امکان می توان مشخصات یک متغیر را در متغیر دیگر کپی کرد برای این کار از قسمت Copy Properties استفاده می گردد.
در قسمت Unlabeled Values گزینه Automatic Labels وجود دارد، با استفاده از این گزینه spss به صورت اتوماتیک یک برچسب برای هر متغیر تعریف می کند که معمولاً مقدار را به عنوان متغیر بر می گزیند.
در انتها با انتخاب ok می توان تغییرات ایجاد شده را تایید کرد و برای تغییرات دوباره از گزینه Reset استفاده کرد.
9357258425
info@pajuha.ir
سفارش ترجمه تخصصي
مرتب سازی موارد در SPSS
بر اساس مقوله متغیرها به دو حالت نزولی و صعودی فایل داده ها را مرتب می نماید.
گاهی محقق درصدد است تا داده ها را بر اساس یک یا چند متغیر به گونه ای صعودی یا نزولی نرتب کند تا بتواند به راحتی از آن برای تحلیل استفاده کند. مرتب کردن داده ها به دو صورت انجام می گیرد:
مرتب کردن داده ها به صورت صعودی (Ascending): در این روش، مقادیر متغر یا متغیر های انتخاب شده به صورت صعودی (از کوچک ترین کد تا بزرگ ترین کد) مرتب می شود.
مرتب کردن داده ها به صورت نزولی (Descending): در این روش، مقادیر متغیر یا متغیرهای انتخاب شده به صورت نزولی (از بزرگ ترین کد تا کوچک ترین کد) مرتب می شوند.
نحوه اجراء
دستور Data -> Sort Cases را اجراء می کنیم.

متغیر یا متغیرهای مورد نظر برای مرتب کردن را وارد کادر Sort by کرده و از قسمت Sort Order، یکی از حالت های Sort Order (صعودی) یا Descending (نزولی) را بنا به هدف مان انتخاب می کنیم. دکمه Ok را کلیک می کنیم.
نکته: موضوع مهمی که در مورد اجراء دستور Sort Cases می توان گفت این است که در هنگام اجراء این دستور، همواره پاسخگویانی که دارای مقدار نا معلوم و گمشده باشند، این مقدار نا معلوم به عنوان کوچک ترین مقدار در بین داده ها تلقی می شود.
09357258425
info@pajuha.ir
سفارش ترجمه تخصصي
ادغام پرونده ها در SPSS
داده های دو فایل بر اساس کیس ها و متغیرها با رعایت شرایطی ادغام می شوند. شرط ادغام به صورت کیس باید نام متغیرها و کد های متغیرها کاملا یکسان باشد و در ادغام متغیر نباید نام متغیرها یکسان باشد.
معمولاً در تحقیقات اقتصادی و اجتماعی، محقق با حجم بالایی از داده ها سر و کار دارد که از طریق تکمیل پرسشنامه با تعداد زیادی از پاسخگویان مثلاً ۱۰۰۰ نفر به دست آمده است. سر شماری های مختلفی که از سوی سازمان ها و نهاد های مختلف دولتی در سطح کشور اجراء می شوند، مانند سر شماری عمومی نفوس و مسکن، آمارگیری از شرکت های تعاونی، سر شماری از محصولات کشاورزی، تمامی تحقیقات ملی و … از جمله این موارد اند که حجم نمونه و به عبارتی تعداد پاسخگویان در آن ها بسیار زیاد می باشد.
از طرفی، به دلیل حجم بالای پاسخگویان در این گونه تحقیقات، معمولاً محقق کار ورود داده به نرم افزار SPSS
را به چندین نفر می سپارد. طبیعی است که بعد از اتمام مرحله ورود داده ها به نرم افزار، از آنجا که چند نفر اطلاعات پرسشنامه را وارد نرم افزار می کنند، محقق با چندین فایل به تناسب تعداد این افراد مواجه است. اما در هنگام پردازش و تحلیل داده، محقق باید تمامی این فایل های مجزا را در قالب یک فایل منسجم ادغام کند. برای این کار دستوری به نام Merge File در نرم افزار SPSS تعبیه شده که محقق می تواند از طریق آن، تمامی فایل های مجزا را در یک فایل ادغام کند.
حالت های Merge File
Add Cases: زمانی که بخواهیم پاسخگویان (موارد) چند فایل را با هم ادغام کنیم.
Add Variables: زمانی که بخواهیم متغیرهای (سوالات) چند فایل را با هم ادغام کنیم.
نحوه اجراء
۱- ابتدا فایل اصلی مان را که قصد داریم داده های فایل دوم به آن اضافه شود، باز می کنیم.
۲- دستور Data->Merge Files-> Add Cases … را اجراء می کنیم.

۳- در پنجره ای که باز می شود، گزینه Browse را انتخاب می کنیم.

۴- فایل دوم را از درایو مورد نظر انتخاب می کنیم و دکمه Open را کلیک می کنیم.

۵- با اجراء دستور قبلی، پنجره جدیدی باز می شود که در آن، محل فایل مورد نظر در کادر به صورت نشان داده می شود، سپس، دکمه Continue را کلیک می کنیم.
 ۶- در پنجره ای که باز می شود، در سمت راست متغیرهای مشترک در هر فایل، و در سمت چپ متغیرهای متفاوت در فایل دوم نسبت به فایل اول نشان داده می شود.
۶- در پنجره ای که باز می شود، در سمت راست متغیرهای مشترک در هر فایل، و در سمت چپ متغیرهای متفاوت در فایل دوم نسبت به فایل اول نشان داده می شود.
 ۷- دکمه OK را کلیک می کنیم که در نهایت، شاهد اضافه شدن پاسخگویان فایل دوم به انتهای فایل اولی خواهیم بود.
۷- دکمه OK را کلیک می کنیم که در نهایت، شاهد اضافه شدن پاسخگویان فایل دوم به انتهای فایل اولی خواهیم بود.
9357258425
info@pajuha.ir
سفارش ترجمه تخصصي
تحلیل آماری – آزمون آماری
موضوع آزمون آماری زمانی مطرح می شود که محقق درصدد کشف، تبیین و کنترل پدیده ها باشد. بنابراین، زمانی که قصد داریم صرفاً به توصیف داده ها بپردازیم، موضوع آزمون آماری اعراب ندارد و هیچ گاه نمی توانیم از آزمون های آماری استفاده کنیم. آزمون های آماری این احتمال را بیان می کنند که آیا نتایج تحقیق در اثر شانس
بوده است یا خیر. تمامی این آزمون های آماری به یک مقدار P (مقدار احتمال) ختم می شوند که این مقدار، اساس پذیرش معنی داری آماری نتایج می باشد. بدین صورت که زمانی به احتمال پایین شانسی بودن نتایج پی می بریم که مقدار P از مقدار مورد توافق جامعه عملی یعنی 05/0 کوچک تر باشد. تنها در صورتی که مقدار P به دست آمده از 05/0 کوچک تر باشد، می توانیم به ارائه یک تفسیر علمی از نتایج مبادرت نماییم. پس، زمانی که مقدار P از 05/0 بزرگتر باشد، آنگاه باید گفت که نتایج در اثر شانس حاصل شده اند و لذا نمی توان تفسیر علمی از نتایج ارائه داد.
بنابراین به طور خلاصه باید گفت که سطح معنا داری در اجرای آزمون های آماری نشان از سه مفهوم است:
1- مقدار P کوچک تر از 05/0 نشان می دهد که شانس و تصادف تنها در مورد کمتر از 5 نفر از هر 100 نفر پاسخگو اتفاق است.
2- موقعی که یک حادثه یا واقعه در اثر شانس اتفاق نیافتاده باشد، آنگاه می گوییم که وقوع این حادثه از لحاظ آماری معنا دار است.
انواع آزمون های آماری
آزمون های آماری، بر اساس ملاک هایی مانند مقیاس داده ها، توزیع داده ها و … ، به دو دسته کلی آزمون های آماری پارامتری و آزمون های آماری ناپارامتری تقسیم می شوند که هر یک شرایط کاربرد خاص خود را دارند.
شناخت نوع آزمون آماری برای فرضیه تحقیق، از فاکتور های مهمی است که به محققین در دست یابی به نتایج متقن کمک می کند. به دلیل اهمیتی که شناخت ویژگی ها مختصات انواع آزمون های آماری و پارامتری در آزمون فرضیه های تحقیق دارد، به شرح مختصات هر یک پرداخته می شود.
آزمون های آماری پارامتری را می توان مؤثر ترین نوع آزمون ها دانست. برای استفاده از آزمون های پارامتری، پیش فرض هایی لازم است که باید در اجراء رعایت کنیم. این پیش فرض ها به چگونگی توزیع نمرات داده و نوع مقیاس مورد استفاده بستگی دارد.
1- هر یک از موارد مشاهده شده مستقل از هم هستند. یعنی انتخاب یک مورد، به انتخاب هیچ مورد دیگری وابسته نیست.
2- واریانس نمونه ها برابر یا تقریباً برابر است. این مطلب، زمانی که حجم نمونه کم است، از اهمیت خاصی برخوردار است.
3- داده ها در سطح سنجش فاصله ای و نسبی می باشند. (یعنی کمی هستند).
4- توزیع داده ها در جامعه، نرمال (بهنجار) و یا نزدیک به نرمال است.
5- تمامی آزمون های آماری پارامتری، میانگین یک یا چند متغیر را در یک گروه یا بیشتر مقایسه می کنند.
برای استفاده از آزمون های ناپارامتری، رعایت پیش فرض های زیر در خصوص توزیع نمره داده ها و نوع مقیاس مورد استفاده لازم است:
1- نرمال بود (بهنجار بودن) توزیع جامعه ای که نمونه از آن انتهاب شده، معلوم نمی باشد.
2- داده ها در سطح سنجش اسمی و ترتیبی می باشند (یعنی کیفی هستند)
3) تمامی آزمون های آماری ناپارامتری، میانه یک یا چند متغیر را در یک گروه یا بیشتر مقایسه می کنند.
9357258425
www.pajuha.ir
info@pajuha.ir
سفارش ترجمه تخصصی


درباره این سایت